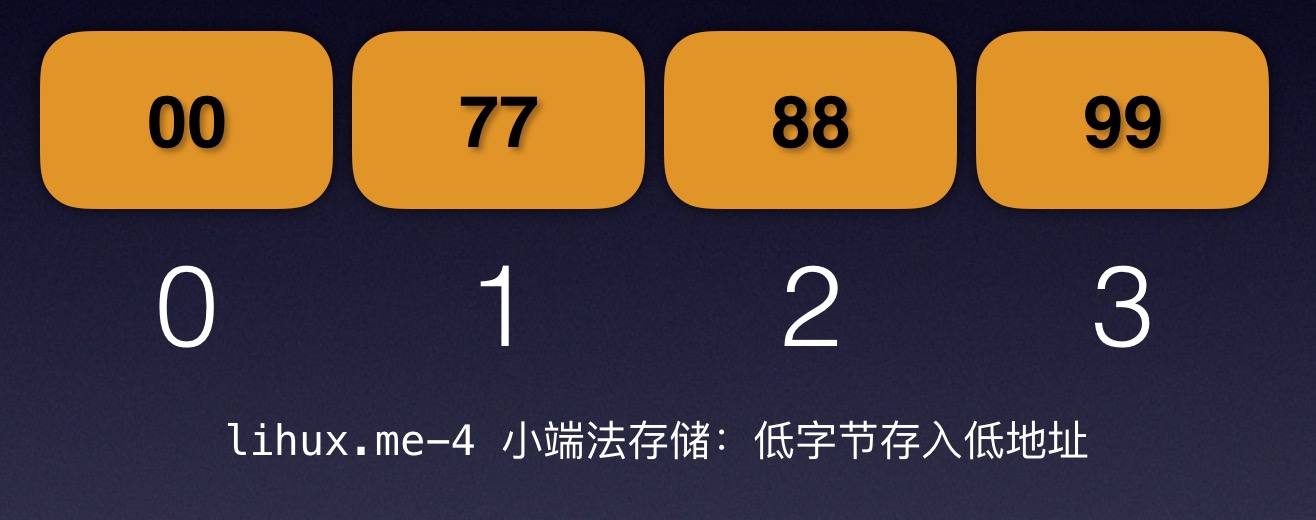
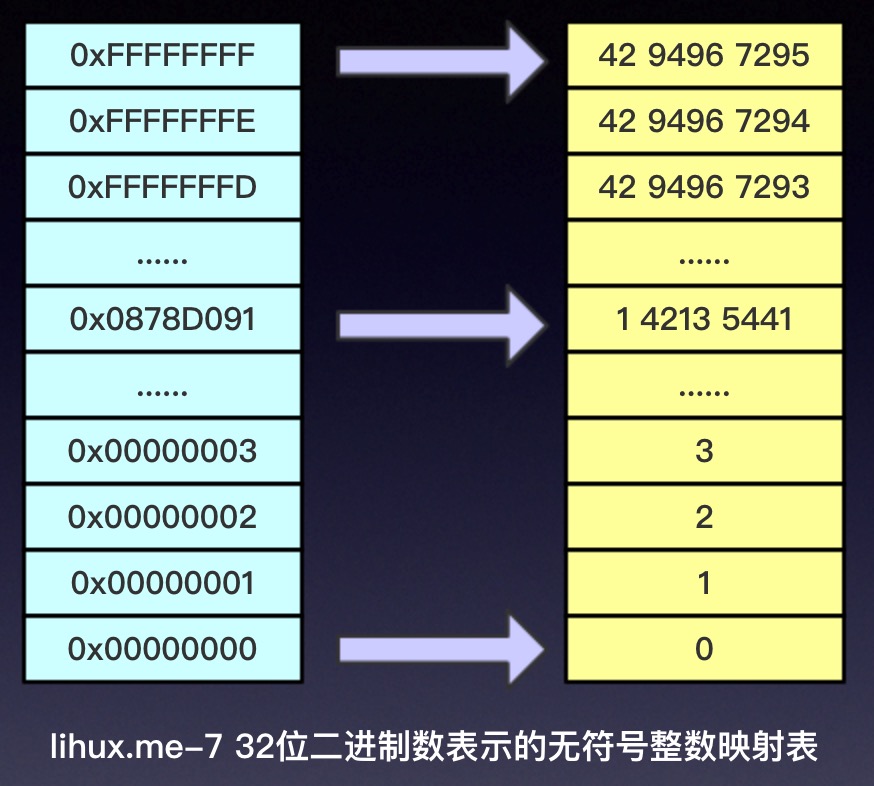
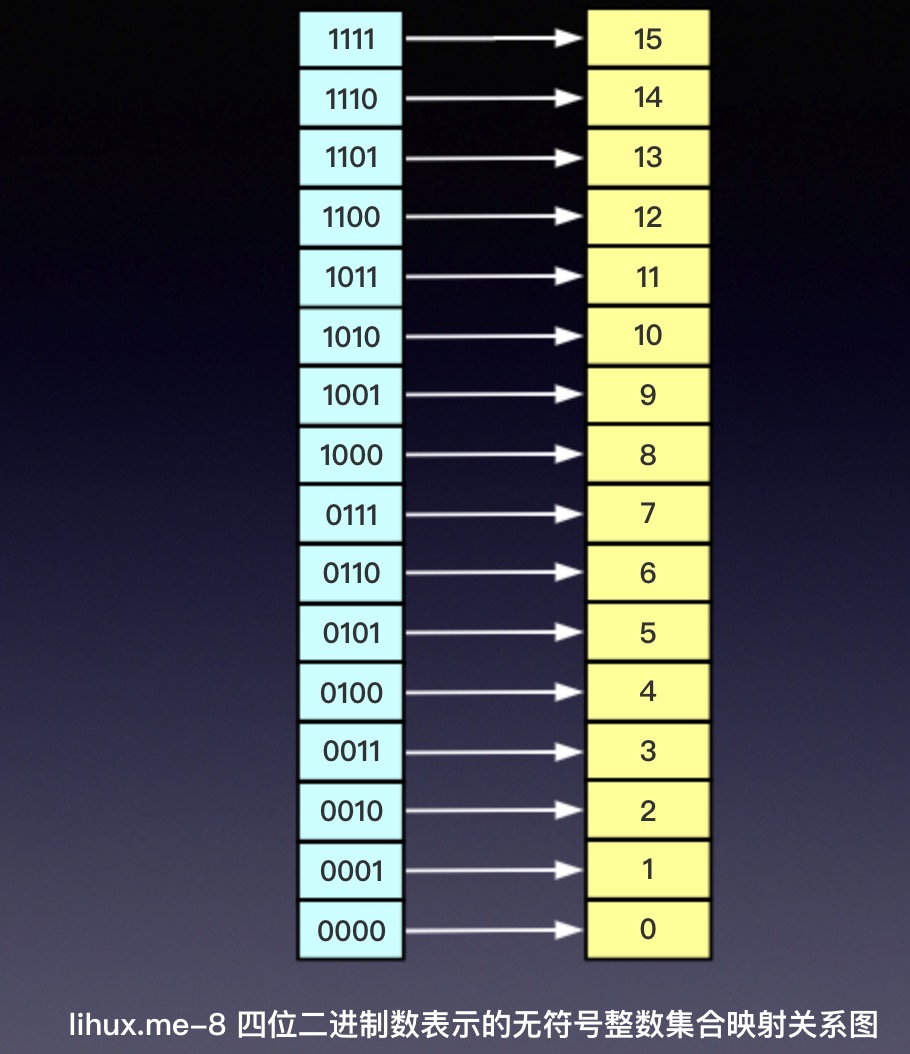
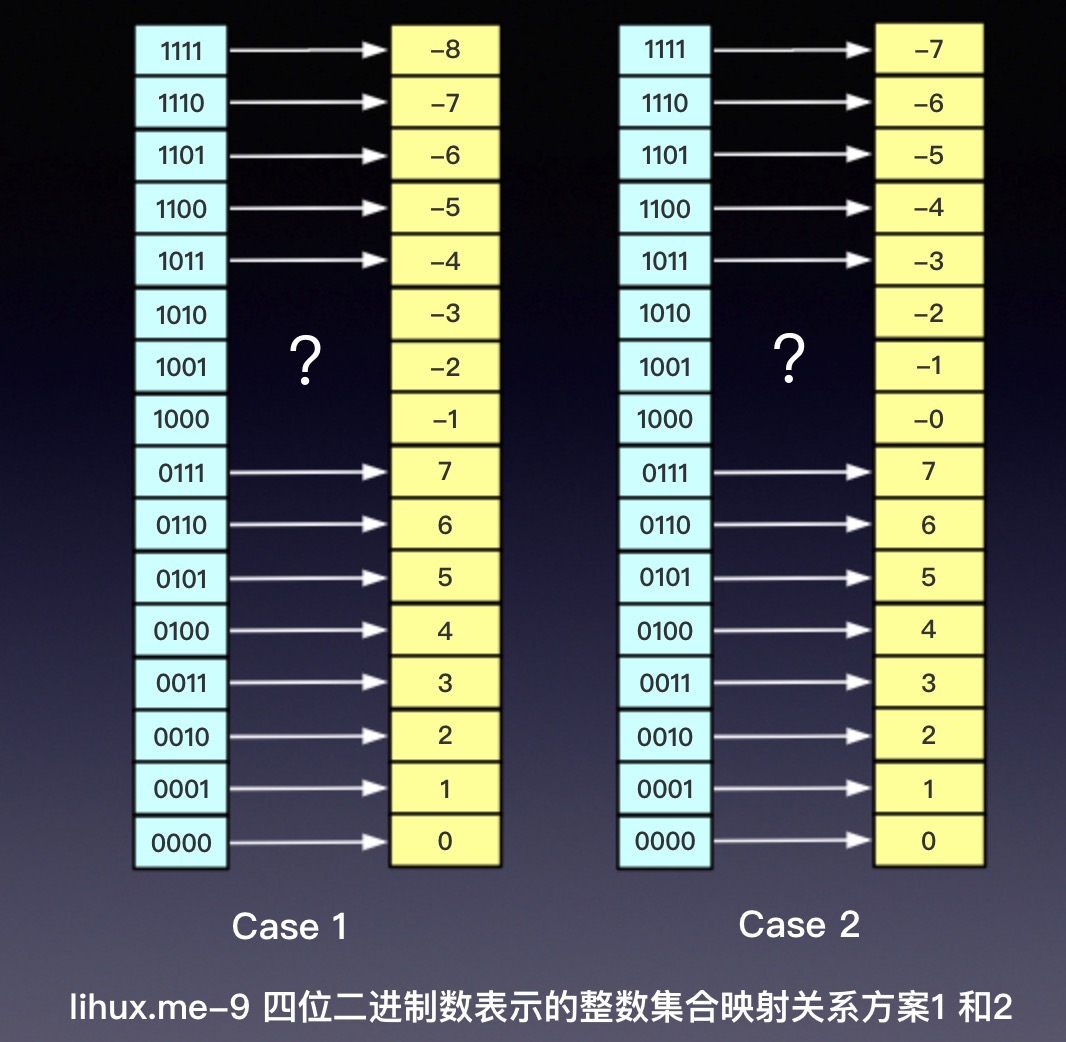
在写了十几本日记和近10年QQ日志之后,终于觉得要移步到中老年人聚集地—-微信上面来写写东西了。时代在进入,我也在成长(变老),与时俱进没毛病。
至于写点儿什么,读者群里是什么,说实话我目前还是稍微有些不清楚,以我之前写日志的过往来看,可能闲散之文会多一些。慢慢的也许会想技术方向倾斜,但又不想局限于技术,也许最终圈出来的一小波人将会是文一些的互联网技术从业者吧。就让时间带给我们答案吧。
作为一个读了一些书(有点儿知识但不一定有文化)、扎根于互联网行业的80后的我来说,从现在开始,给自己一点小小的改变,向外输出一些温暖的、正能量的、有意义的内容,是我觉得有意义、值得去做的事情。
这里不会有标题党,也不会贩卖焦虑,它只见证这个时代大脉搏下的一个小小参与者的成长历程。从一个更长远的角度来看,它也许是一个人毕生发展都可以与之为伴的小小驿站。
希望能在这里遇见一批志同道合的朋友,见证彼此的成长。
未来已来,让我们拭目以待!